Every day, people turn to a variety of search engines including Google, Bing, Yandex, Baidu, Kagi, and Marginalia to find information on the internet. Each has a different set of advanced proprietary techniques for choosing the most relevant, highest quality search results. But how do these systems work? In this project from EECS 485 (Web Systems), I implemented a search engine using the well-known TF-IDF ranking formula. It analyzes the text and links of documents and assembles this information into an index that allows pages to be quickly found by their keywords and ranked by quality. It also includes a service for querying this information (the index server), and a search server with a frontend for users that queries the index server.
Since this is a university project, the honor code disallows me from sharing the full source code, but you can read the spec document.
The search engine is composed of three main components: the inverted index pipeline, the index server, and the search server. The inverted index pipeline is responsible for processing the HTML documents in the corpus and creating an inverted index. These documents would normally be retrieved from a web crawler, but creating a web crawler was not in scope for this project. The inverted index is an on-disk data structure mapping each term to all documents that contain it, along with some other relevant information about the term's overall frequency and per-document frequency. The index server is responsible for handling queries from the search server and returning the search results by processing results from the inverted index. There are multiple index servers, and each is responsible for a different set of documents. The search server queries the index servers, merges results from them, and displays the search results to the user.
TF-IDF is one algorithm used to rank search results according to a query. The idea behind TF-IDF is that terms that appear frequently in a document but rarely in the corpus are more important to that document than terms that appear frequently in the corpus. For example, the term "the" appears frequently in most documents, so it is not very informative. However, the term "Google" appears frequently in documents about Google, but rarely in other documents, so it is more informative.
The TF-IDF score of a term in a document is a measure of how important that term is to the document. It is calculated as the product of the term frequency (TF) and the inverse document frequency (IDF). The term frequency is the number of times the term appears in the document, and the inverse document frequency is a measure of how rare the term is in the corpus. The formula for TF-IDF is:
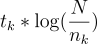
where tk is the term frequency of term k in the document, N is the total number of documents in the corpus, and nk is the number of documents that contain term k. To rank documents according to their relevance to the query, the search engine calculates the cosine similarity between the query vector and the document vectors, both of which contain weights calculated according to TF-IDF. TF-IDF scores for the query are calculated the same way they are for any document, as queries can be considered a kind of very short document.
The input to the inverted index pipeline is a set of HTML documents, each in a separate file. The desired output is a text file containing a set of terms, with the following information stored about each:
The document processing is done by a series of MapReduce programs written in Python. MapReduce is a paradigm for data processing where programs are organized into alternating map and reduce stages. The map stage transforms the input data to select the relevant features, and chooses the key by which items will be grouped for the reduce stage. Before each reduce stage, the input data is sorted lexicographically to group keys. Then, the reduce stage computes some new output for each group. This data is then fed into the next map stage, if it exists, and so on. The advantage of writing programs in the MapReduce paradigm is that it gives unlimited parallelism for data processing because the work can be divided among many machines.
As much as I'd like to give specifics about the input, output, and implementation of each stage, I don't think my professors would be too happy with me if I did! What matters is that after this pipeline is complete, the data is in a format that is easy to index and calculate TF-IDF scores for.
The index server is a web service that handles queries from the search server and returns search results. It is implemented in Python using the Flask web framework. The index server reads the inverted index from disk and stores it in memory for fast access. When a query is received, the index server processes it and returns the search results to the search server, ranking them using the cosine similarity of TF-IDF scores and PageRank. As an example of how cosine similarity is calculated, imagine calculating the ranking of a document containing the terms ["Google", "is", "a", "search", "engine", "for", "the", "web"] relative to a search query containing the terms ["web", "search"]. The two vectors would look like this, where each number is a TF-IDF score:
| Term | Document | Query |
|---|---|---|
| 1.7 | 0 | |
| is | 0.1 | 0 |
| a | 0.1 | 0 |
| search | 1.2 | 2.0 |
| engine | 0.9 | 0 |
| for | 0.1 | 0 |
| the | 0.08 | 0 |
| web | 1.3 | 2.0 |
We normalize both vectors, then compute their dot product, giving the cosine similarity. The index servers determine ranking based off of a weighted sum of this cosine similarity with a PageRank score. While PageRank was taught in detail in the class, I did not implement it in this project and instead used a pre-computed PageRank score given by the instructors.
For this project, there were 3 index servers, with each storing an index relevant to 3 mutually exclusive sets of the corpus of documents. This shows one way to horizontally scale a web search service. In the database world, this is known as sharding. To improve reliability and load-balancing, we also could have used replication, where multiple servers store the same data so that if any of them go offline the data is still accessible via other servers.
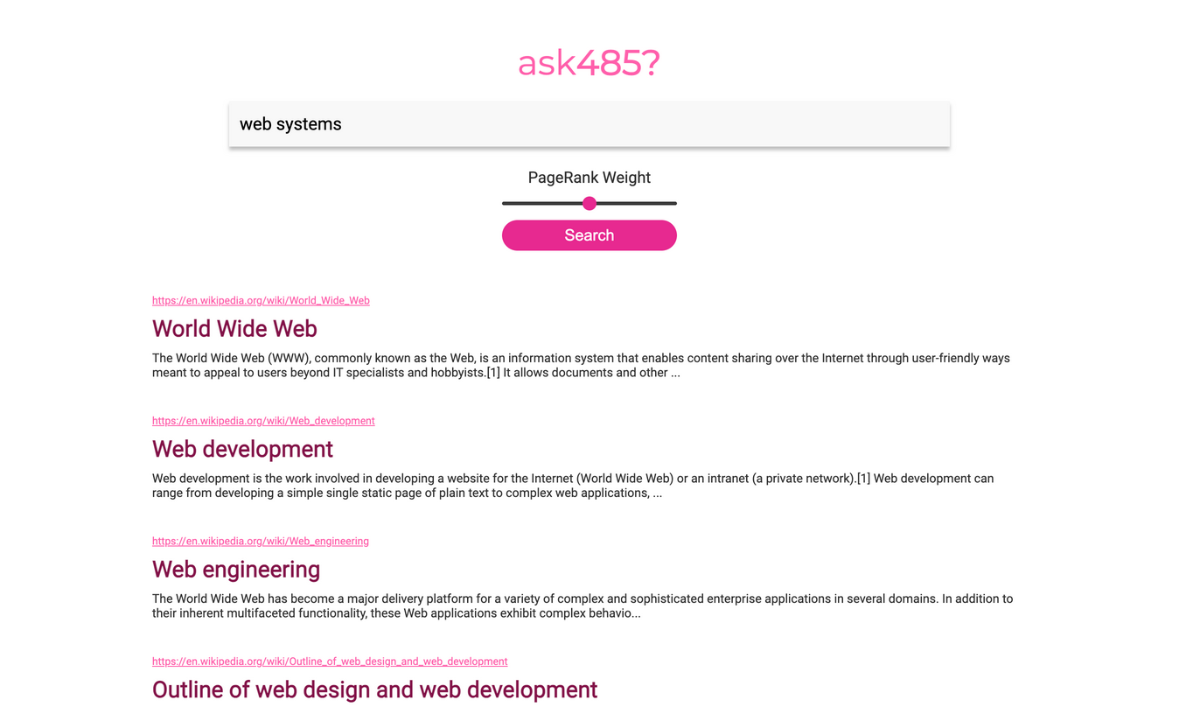
The search server is a web application that allows users to enter a search query and displays the search results. It is implemented with Flask, and uses forms instead of JavaScript for interactivity. This server sends queries to the 3 index servers, merges their results, and displays them to the user. The search server contains a slider allowing users to balance the importance of PageRank score and cosine similarity of TF-IDF scores. Each search result includes a title, snippet, and URL, so users can quickly determine if the search result is relevant to their query.
The two main things missing from this project are a web crawler and PageRank implementation. A web crawler would allow the search engine to index the entire web, which is a vital part of any real search engine. Due to time limitations, the instructors did not ask us to implement PageRank, and instead gave us the PageRank scores for each page in a text file to be parsed. However, given more time, this would be a great extension of the project. There is also room for improvement in terms of the search matching criteria and ranking algorithm. For example, the search engine could be extended to support more advanced search queries, such as phrase search, wildcard search, and boolean search. The engine could use stemming or lemmatization to standardize terms, and could also identify synonymous words in documents and queries. The ranking algorithm could be improved by incorporating more factors, such as the position of the search terms in the document, the number of times the search terms appear in the document, and the number of links to the document.